Twin training: trick for better model comparisons
Abstract: Frequently comparing deep learning models?
A simple way to improve comparison is discussed here,
this trick becomes specially handy when comparing segmentation models.
Reliable comparison of models is a question important for DL “theorists” (to evaluate new approaches) as well as for practitioners/engineers (to select an approach for a particular task in hand). Comparison is time-consuming process, frequently with noisy results.
Usual setting incorporates fixed dataset split into train/val/test and fixed metric of choice. Next, independent runs are conducted for all models under comparison and achieved quality is registered.
As a result,
- There is a significant noise in comparison (it is rare to rerun each model several times, specially in applications),
- Validation can be done only using whole dataset
- need to remember which version of code was used to generate a particular number, as you can
accidentally compare things that are not ‘comparable’ because of e.g. changed augmentation or updates in the dataset
- yes, practitioners have to deal with frequent updates in the dataset
- can’t use augmentations while testing, since it is hard to guarantee that exactly same augmentations were applied. Sometimes it is handy to evaluate using several batches as a fast intermediate check. Augmentations in test allow ‘broader’ check.
What is suggested: twin training
Models can be trained side-by-side within the same process, with as high similarity in the training process as possible. Same batches, same augmentations, and of course the same datasets.
- If models, say, have identical architecture, their initial weights should be identical (easy to achieve in any DL framework).
- As we know, initial state influences optimization, in some cases drastically (that’s not desirable, but happens).
- During training, same exact batches with the same exact augmentation should be used to optimize models.
- That’s right, you need to augment only once, thus CPU is not a bottleneck.
- Similarly, one should always compare on the same batches. To achieve smooth monitoring rather than ‘validate once on a while’, take one batch at a time and compute metrics on that batch.
Pseudo-code may look like (fragment):
for batch in train_data:
batch = augment(batch)
for model in models:
# make an optimization step for each model using the same batch
Things usually tuned (architecture, loss, augmentations, parameters, optimizers, learning schedules, etc.) - all of them can be compared more efficiently this way.
Example:
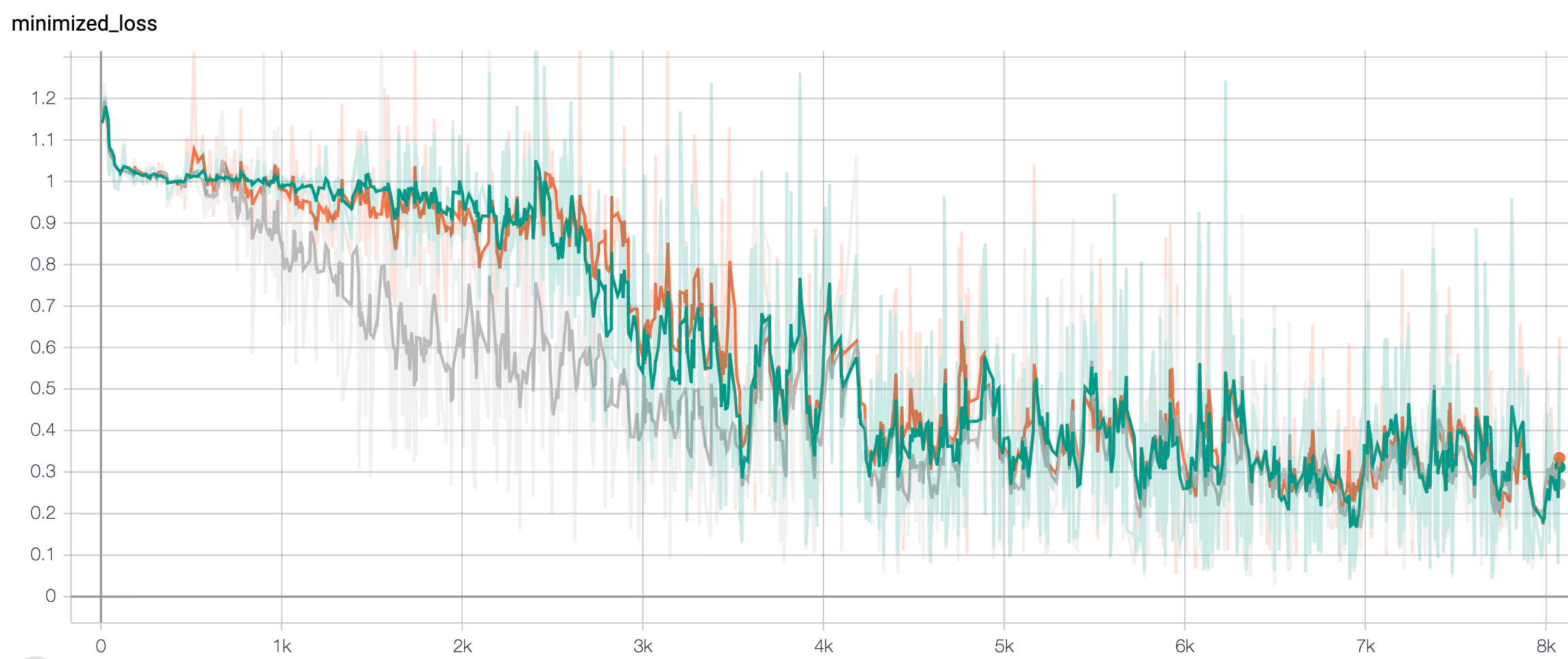
There are three models trained in parallel in this screenshot from tensorboard. One can tell when one of models has lower loss and estimate level of ‘noise’. It is also clear that most jumps and falls in learning curves are due to batches sampled, and are not model-specific behavior. In other words, you can better see the difference between models not difference between runs.
This demonstrates a typical comparison — things compared are extremely similar and there is little practical difference. Models’ response to the same training input is close to identical. It’s not easy to get the same conclusion by looking at just final scores. That’s a good argument towards including learning curves in the paper.
Bonus: simpler comparison of segmentation models
When training models for image segmentation (such as instance segmentation or class-segmentation), lack of memory becomes a critical factor. Batch sizes become very small, and it is almost impossible to train several segmentation models at once on a single GPU.
During segmentation training each sample contributes a lot, since it provides a lot of labels (one per pixel!).
It is also unlikely that you have thousands of well-labelled high-resolution segmentation images.
However when you train several models inside a single script/notebook, there are no such problems, because you never keep intermediate activations for more than one model at a time. Weights of all models should still be kept in (GPU) memory, but that’s a small fraction of space taken by activations.
Bonus: simple organization of experiments in tensorboard
Tensorboard recursively scans subfolders for logs, so you can keep each ‘comparison’ in a separate folder, and each compared option saves its logs to a corresponding subfolder.
Alternative: fix random seed?
I don’t think that fixed random seed is reliable enough to be considered as an alternative way to achieve similarity in training.
THere are many different RNGs provided by different modules, and RNGs are used in too many places.
And you need to precisely control RNG flow in your program.
Because if some of your functions use global RNGs like random or np.random directly,
this implies that any side call to those from anywhere in your program completely changes all following sampled numbers.
Any ‘interruption’ in the sequence breaks it.
Random numbers on GPU is whole another story.
So, you should look through all the augmentations, samplers, dropouts (basically, everything) to verify they don’t use global RNG’s (and find that some of them actually do).
Long story short, if you have to rely on random seeds in DL, at least log some control sums to verify that sequence was not broken by an unexpected call from somewhere else.
You can still use random seed to achieve reproducible training of the same model.
 Gradient boosting
Gradient boosting  Hamiltonian MC
Hamiltonian MC  Gradient boosting
Gradient boosting  Reconstructing pictures
Reconstructing pictures  Neural Networks
Neural Networks