Detailed research projects
(click for details)
CAPE: Encoding Relative Positions with Continuous Augmented Positional Embeddings
- Transformers' attention mechanism is permutationally invariant (making "cat eats fish" and "fish eats cat" identical to transformers).
- Positional embedding is a common way to provide missing information about the order. We propose a simple yet extremely efficient and flexible strategy by augmenting encoded positions during training.
- We experimented with computer vision, speech recognition and machine translation to confirm better generalization and wide applicability of our method. Along the way we found that out method by design handles well different resolutions and stft sampling frequencies.
- Read paper
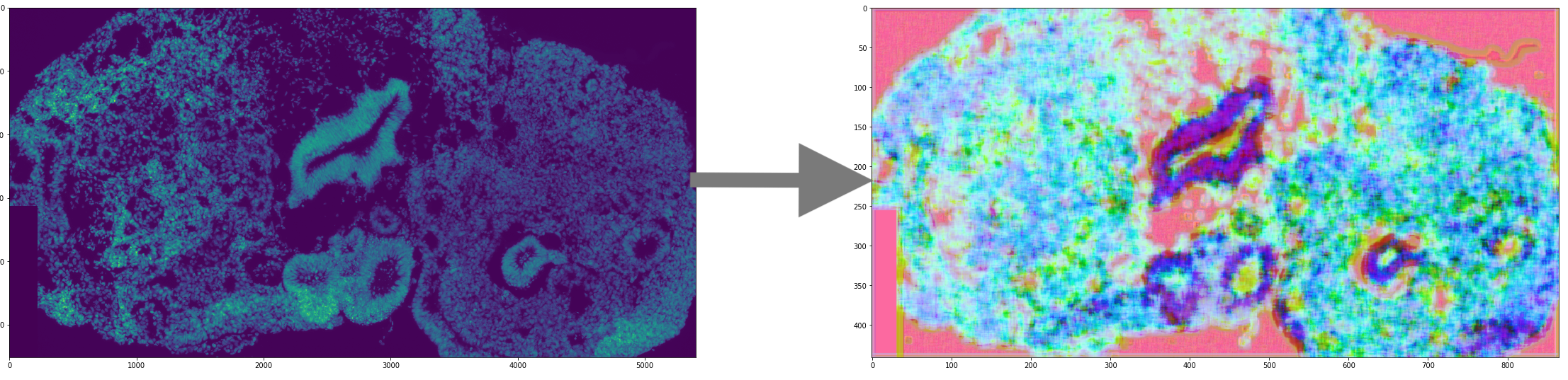
Demultiplexer for single-cell RNA-sequencing
- Single-cell transcriptome sequencing - technique which employs next generation sequencing to estimate RNA content of individual cells.
- Multiplexing is a technique widely used to compare RNA profiles of different tissues (e.g. diseased vs healthy) within the same pipeline. Cells from different tissues (e.g. organoids) are pooled and then processed together.
- Demultiplexing is an inverse operation done computationally - by looking into resulting reads we try to guess which donor this cell could come from. Fortunately, everyone's genotype is unique (ok, almost everyone's) and these variations can be used by demultiplexing.
-
My project is going further and learns genotype-specific polymorphisms from RNA-sequenced data to complement data known from
GSA.
Resulting algorithm has ~4-5 times less error compared to demuxlet, which allowed to significantly increase a number of donors considered, which was critical in our case.
One-shot learning for analysis of organoid variability from microscope images

Developed a method to describe organoid morphology from brightfield imaging without manual labelling. Demonstrated its power by predicting gene expression levels from images as well as various visual phenotypes.
Decomposed variability to contributing factors to guide following decisions on minimizing variability. Method is so sensitive it notices minor changes in protocol.
Unsupervised tissue characterization from IHC
Model was trained to describe tissue structure by providing a vector description for each segment, which allowed automated comparison and search for similar tissue.
Einops — new deep learning operations
Einops is a package and notation that reconsider tensor manipulations. Working on top of leading deep learning frameworks, einops makes code shorter, more readable and reliable.
Einops is used by dozens of AI labs in hundreds of open-source projects.
Text-to-speech for Russian language
Leading development of speech synthesis technique that employs only neural networks. None to an adorable chatter in 2 months.
Few-shot learning for face recognition
Building a system for face identification/verification based on deep learning. The system is optimized to run on mobile devices and to deal with few-shot learning scenario (i.e. very few training samples for each person).
InfiniteBoost: building infinite ensembles with gradient descent (with T.Likhomanenko)
InfiniteBoost is a modification of gradient boosting that converges when a number of trees in the ensemble tends to infinity. In this approach, it is also possible to introduce automated tuning of capacity (it is a parameter that is similar to learning rate in gradient boosting). Read more
Particle identification at the LHCb (with D.Derkach, M.Hushchyn, T.Likhomanenko)
LHCb is one of four major experiments at the LHC, and it is a bit different from other experiments — LHCb is single arm, and analyzes particles in quite limited angle. However, the advantage of this scheme compared to other experiments, is that LHCb provides more information to identify particles, which makes it more precise in studies of b-physics.
We prepared a major update of particle identification system with deep networks and GBDT. Important part was preparing models which are independent on momentum using an approach from "Boosting to uniformity" (see below). Read more
Finding electromagnetic showers in the OPERA
The OPERA is an experiment placed inside a mountain in Italy, it was created to confirm neutrino oscillations (Nobel prize 2015). In this project I've created a system that detects electromagnetic showers in the data collected by the OPERA. That is, among millions of base tracks it finds a small pattern of ~ hundred base tracks. Needle-in-a-hay problem with tough computational requirements. Read more
Reweighting with Boosted Decision Trees
An important problem of many analyses in high energy physics is a discrepancy between simulated data and real data. An approach used previously to reduce this effect can only handle discrepancies in 1-2 variables.
An algorithm was proposed that directly solves reweighting problem in many dimensions and additionally addresses some issues important for LHCb analyses, such as handling negative weights (so-called sWeights). This tool is used in LHCb analyses. Read more
Inclusive flavour tagging at the LHCb (with D.Derkach, T.Likhomanenko)
Guessing flavour of a neutral (non-charged) meson isn't easy, but required to estimate some of the standard model parameters. This information can be partially reconstructed by analyzing tracks left by other particles produced after collision.
We came up with a simple probabilistic model which combines information from all the other tracks — and it works better than previous approaches, where separate analysis was performed for each type of tagging particles and for each meson. Read more
Later I've tried to improve the system by including attention-like mechanism. This helps when amount of training data is limited. Read more
Boosting to uniformity (main author, with A. Bukva, V. Gligorov, A. Ustyuzhanin, and M. Williams)
Various statistical dependencies may be easy to use to improve classification, but are undesirable to influence our decisions (simplified examples are gender and race when using ML in hiring). Simply removing these features from training may not be sufficient, since other features may still have this information (e.g. photo in CV helps easily guess the gender, in some languages gender of a writer can be inferred from the text).
We developed a method that is capable of suppressing dependency between classification result and one or more selected variables using specific loss (that is based on Cramer-von Mises criterion). Read more
Tracking in the COMET (with E. Gillies)
The COMET is an experiment in high energy physics currently under construction in Japan targeted at finding charged LFV transitions. The goal was to prepare a fast system that efficiently selects candidate events for transitions.
Using machine learning coupled with a soft modification of Hough transform we were able to improve wire-level recognition quality: ROC AUC from 0.95 to 0.9993. Read more
Inclusive trigger for the LHCb (contributing author)
Millions of collisions should be analyzed each second at the LHCb experiment, which is an enormous amount of data (that can't even be stored), so the experiment uses online triggers that decide which collisions to store and which can be deleted.
Our team developed new trigger system based on MatrixNet (Yandex proprietary GBDT modification). I was responsible for speeding up the model and managed to compress an already trained MatrixNet ensemble from 10'000 trees to 100 without significant drop in quality. Read more
Optimal boundary control of oscillations in distributed systems (PhD thesis)
I was in a group led by Vladimir Il'in (wiki) and investigated the problems of optimal boundary control of oscillations described by wave equation (exciting / damping of particular oscillations by actively interacting with a system at the boundary). Typical approaches investigate numerical algorithms to find an approximate solution, our group developed methods to solve the problem analytically, hence precisely and more efficiently.
I've introduced a special notation based on operator matrices to describe the problem and provided optimal solution of control problem for composite rods/strings of multiple parts (previous results covered only very specific case with two parts and additional strong requirements).
This research was selected as "best student's paper in mathematics" by Russian Academy of Sciences in 2012.
Computing properties of dense loop model using duality with spanning web model
This is a research in solid state theory: both dense loop model and spanning web model are lattice models (and have corresponding partition functions), their nice duality made it possible to compute partition function and loops density of dense loop model. Read more (my part is computations for web models).