Schema migration should be a responsibility of DB
A great achievement of the past decade in programming is a shift in paradigm from transition-focused to state-focused.
This shift is clearly seen in front-end (user interfaces): In react/preact/vue and other frontend frameworks a component has a state and defines how state should be represented (rendered) in html. The aim of a framework is to ‘migrate DOM’ to desired html representation with minimal overhead.
This shift is clearly seen in management of cloud resources. In AWS CDK, pulumi, terraform and other IaC tools user defines desired state of infrastructure, and it is responsibility of a tool to produce a correct ‘migration of infrastructure’.
This shift is visible in dependency management: Dependency management relies on expected state (which packages/libraries are required) and less on imperative instructions that dictate order of installation. Imperative glue here is still very common — e.g. dockerfiles, but tools like nix/nixos eliminate the glue as well.
In databases, in particular in ORMs, this shift had (only partially) happened around two decades ago. User changes ORM classes, and the framework produces migrations.
Generally speaking, in all these cases we define desired state of the system, not necessary changes. Movement to state-focused programming dramatically simplified management of complex systems. It’s like you laying out a plan of street while the question of moving all belongings/walls is solved for you.
What’s wrong with migrations in RDBMS?
Switching to auto-migration tools helps to focus on important - e.g. current relations in RDBMS - and not how we ended up with this set of relations. Plus, coherence between DB and code (ORMs or schema-definition tools) is now granted.
Adoption of auto-migration tools is still very low (even compared to ORMs), and in my opinion, because of how this process is organized.
We have dozens of relational DBMS, and yes, they look similar, but there are tons of nuances that make them all different.
And we have a number of tools to produce migrations: sqlalchemy+alembic in python, entity framework in .net, a dozen of tools for Hibernate in Java, and every community/ecosystem tries to develop a solution that can migrate a large number of deviating databases in a uniform way.
No big surprise all of them have very limited success given that scope of project is unlimited.
Auto-migration tools like alembic are also tough to develop and maintain:
- they need to understand schema definition in a language (in python, in this case)
- they need to introspect current schema of the database
- they need to compute ’diff’ based on matching these two schema definitions, neither of which were created with automated schema migration in mind
- deal with all peculiarities of dialects in schema definition and schema migration
- for all operations alembic creates counterparts in python code, which is like introducing +1 language
The same problems doesn’t hurt frontend frameworks as much, because there are currently ~2.5 browser engines, and a ton of work done by standardization committees around js, and … after ditching react/vue you still have to deal with discrepancies, this time yourself. The same problems are faced by IaC tools, and this eventually will become one more (significant) barrier for migration between clouds.
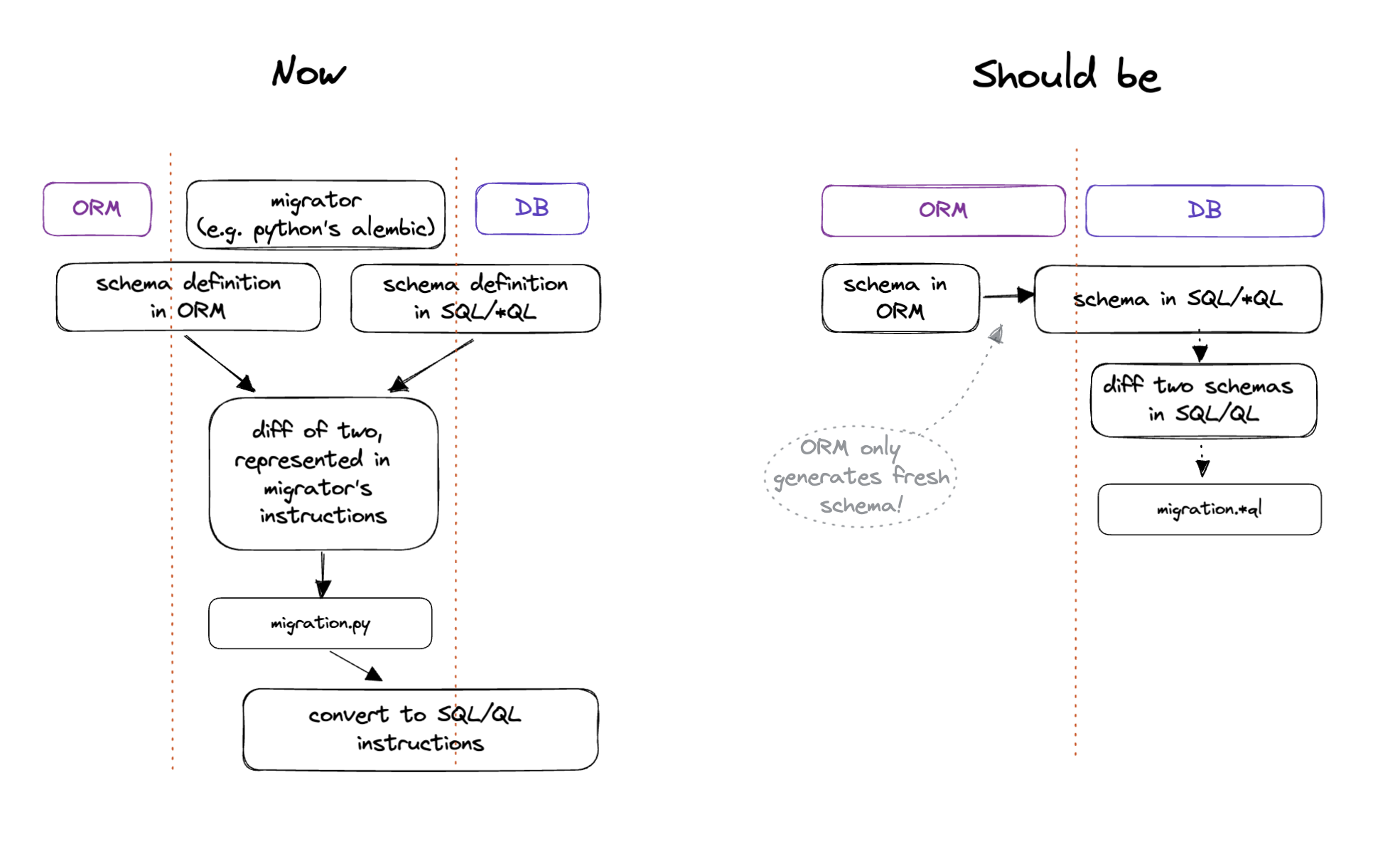 Comparison of existing solutions (python’s alembic is taken as example),
and comparison to this proposal. Note that on the left there are multiple steps that cross the boundary
of ORM/migrator or migrator/DB.
Comparison of existing solutions (python’s alembic is taken as example),
and comparison to this proposal. Note that on the left there are multiple steps that cross the boundary
of ORM/migrator or migrator/DB.
Solution
- schema migration is generated by database
- tool only declares desired state
This will move responsibility for db-specificity migration to db developers, and that’s for good.
Where to start?
In a minimal implementation, DB provides a function. Function is given two db schemas (think of postgresql/oracle/sql server schemas, or individual databases in mysql) and compares them to produce a migration from an observed difference.
Migration tool would create a temporary schema with a desired state and call a procedure to produce migration.
That’s not something unseen: pgAdmin has ‘Schema Diff’, SQL Server Data Tools has ‘Schema Compare’. So tools do exist, but they are not part of the database, and they don’t have a uniform interface.
Consequences
When we push migrations to database developers…
- migrations would be almost immediately available in any programming language
- on a longer range, we should expect improvements in SDL (schema definition languages) to account for common migration scenarios.
Example of these changes
For example, if you start from something like
Relation Person:
name: string
and migrate it to
Relation Person:
full_name: string
From the point of a migration tool it is not clear that you just renamed a field, not deleted ‘name’ and created ‘full_name’. Thus an additional technical identifier is necessary, for instance:
Relation Person:
name: string, oid=‘7dsd8’
to
Relation Person:
full_name: string, oid=‘7dsd8’
now it is clear that renaming happened. There are a number of other ways to have smoother support of migrations.
However, this will be just an idea until DB developers don’t have to think about migration.
- there are cases when db just does not provide tools to produce migrations. Like postgresql enum that just can’t be migrated safely by alembic, so this issue is unresolved for years, and that’s not on alembic side.
Well… we can just implement improvements as a stand-alone solution, e.g. within ORM, right?.
No, we can’t. As I described, to make it somewhat useful, you need to support numerous dialects, and creating such migration tools is a big job (comparable to creating a new database). Creating such tools for multiple languages is probably more job than just creating db from scratch.
That’s the main feature I expect from my next db: declarative SDL with schema migrations taken by DB. I know that EdgeDB already provides such functionality, but if you know other tools that have this implemented - drop me a letter.
 Gradient boosting
Gradient boosting  Hamiltonian MC
Hamiltonian MC  Gradient boosting
Gradient boosting  Reconstructing pictures
Reconstructing pictures  Neural Networks
Neural Networks