Learning to rank (software, datasets)
For some time I’ve been working on ranking. I was going to adopt pruning techniques to ranking problem, which could be rather helpful, but the problem is I haven’t seen any significant improvement with changing the algorithm.
Ok, anyway, let’s collect what we have in this area.
Datasets for ranking (LETOR datasets)
-
MSLR-WEB10k and MSLR-WEB30k You’ll need much patience to download it, since Microsoft’s server seeds with the speed of 1 Mbit or even slower.
The only difference between these two datasets is the number of queries (10000 and 30000 respectively). They contain 136 columns, mostly filled with different term frequencies and so on. (but the text of query and document are available) -
Apart from these datasets, LETOR3.0 and LETOR 4.0 are available, which were published in 2008 and 2009. Those datasets are smaller. From LETOR4.0 MQ-2007 and MQ-2008 are interesting (46 features there). MQ stays for million queries.
- Yahoo! LETOR dataset, from challenge organized in 2010. There are currently two versions: 1.0(400Mb) and 2.0 (600Mb). Here is more info about two sets within this data
Set 1 Set 2 Train Val Test Train Val Test # queries 19,944 2,994 6,983 1,266 1,266 3,798 # urls 473,134 71,083 165,660 34,815 34,881 103,174 # features 519 596 - There is also Yandex imat’2009 (Интернет-Математика 2009) dataset, which is rather small. (~100000 query-pairs in test and the same in train, 245 features).
And these are most valuable datasets (hey Google, maybe you publish at least something?).
Algorithms
There are plenty of algorithms on wiki and their modifications created specially for LETOR (with papers).
Implementations
There are many algorithms developed, but checking most of them is real problem, because there is no available implementation one can try. But constantly new algorithms appear and their developers claim that new algorithm provides best results on all (or almost all) datasets.
This of course hardly believable, specially provided that most researchers don’t publish code of their algorithms. In theory, one shall publish not only the code of algorithms, but the whole code of experiment.
However, there are some algorithms that are available (apart from regression, of course).
- LEMUR.Ranklib project incorporates many algorithms in C++
http://sourceforge.net/projects/lemur/
the best option unless you need implementation of something specific. Currently contains
MART (=GBRT), RankNet, RankBoost, AdaRank, Coordinate Ascent, LambdaMART and ListNet - LEROT: written in python online learning to rank framework.
Also there is less detailed, butlonger list of datasets: https://bitbucket.org/ilps/lerot#rst-header-data - IPython demo on learning to rank
- Implementation of LambdaRank (in python specially for kaggle ranking competition)
- xapian-letor is part of xapian project, this library was developed at GSoC 2014. Though I haven’t found anythong on ranking in documentation, some implementations can be found in C++ code:
https://github.com/xapian/xapian/tree/master/xapian-letor
https://github.com/v-hasu/xapian/tree/master/xapian-letor - Metric learning to rank (mlr) for matlab
- SVM-Rank implementation in C++
- ListMLE, ListNET rankers (probably these were used in xapian)
- SVM-MAP implementation in C++
Some comparison (randomly sampled pictures from net):
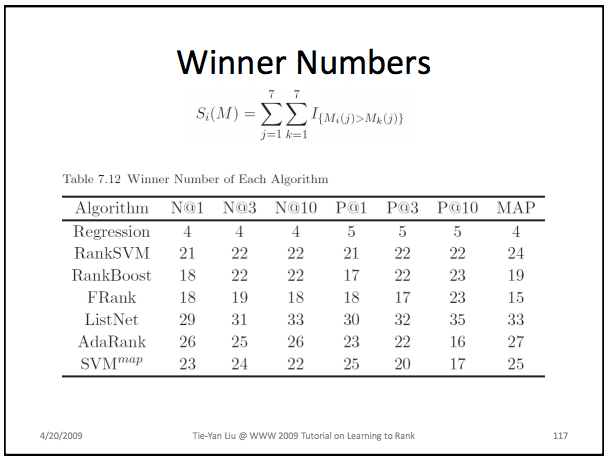
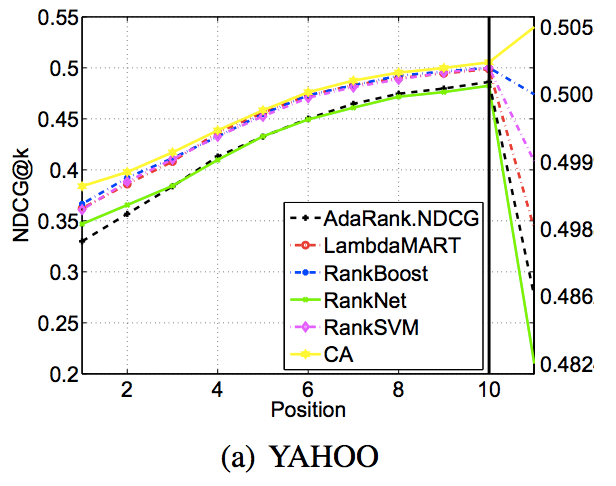
though paper was about comparison of nDCG implementations.
 Gradient boosting
Gradient boosting  Hamiltonian MC
Hamiltonian MC  Gradient boosting
Gradient boosting  Reconstructing pictures
Reconstructing pictures  Neural Networks
Neural Networks