Thoughts about tensor train
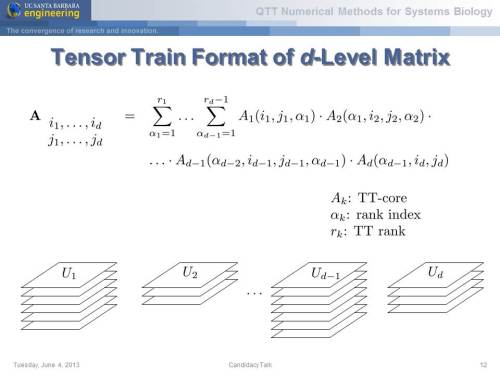
One of the probable approaches to building graphical models with categorical variables is tensor decomposition.
Notably, both tensor decomposition (tensor train format) and the method to use it for graphical models were developed at my faculty, though by different people in different departments.
One more interesting question is the interpretation of those hidden variables emerging in the middle.
At the moment, I’m considering the possibility of integrating this into GB-train, since the trained model for each event provides a sequence of binary visible variables. In principle, this could be written in a relatively simple way. For example, if $x_i$ is a Boolean variable corresponding to the $i$th cut in the tree (or train, more precisely), one could write the partition function as:
\[Z = A_1[x_1, y] A_2[x_2, y] \dots A_n[x_n, y]\]or as:
\[Z = A_1[x_1] B_1[y] A_2[x_2] B_2[y] \dots A_n[x_n] B_n[y]\]In both cases, it’s fairly simple to estimate the posterior probability, since we have only a limited set of options (targets) to evaluate. However, determining which form to prefer and why remains an open question for me.
 Gradient boosting
Gradient boosting  Hamiltonian MC
Hamiltonian MC  Gradient boosting
Gradient boosting  Reconstructing pictures
Reconstructing pictures  Neural Networks
Neural Networks